


Neural Networks are widely used across multiple domains, such as Computer Vision, Audio Classification, Natural Language Processing, etc. In most cases, they are considered in each of these domains individually. However, in real-life settings, it is rarely the case that this is the optimal configuration. It is much more common to have multiple channels, meaning several different types of inputs. Similarly to how humans extract insights using a wide range of sensory inputs (audio, visual, etc.), Neural Networks can (and should) be trained on multiple inputs.
The Multi-Channel Neural Network
Neural Networks can, and should, be trained on multiple types of features. This tutorial walks through how to use the Keras Functional API to augment your networks. Neural Networks are widely used across multiple domains, such as Computer Vision, Audio Classification, Natural Language Processing, etc. In most cases, they are considered in each of these domains individually. However, in real-life settings, it is rarely the case that this is the optimal configuration. It is much more common to have multiple channels, meaning several different types of inputs. Similarly to how humans extract insights using a wide range of sensory inputs (audio, visual, etc.), Neural Networks can (and should) be trained on multiple inputs.
Let’s take, for example, the task of emotion recognition.
Humans do not use a single input to effectively classify the interlocutor’s emotion. They do not use, for instance, the facial expressions (visual), the voice (audio), or the meaning of words (text) of the interlocutor only, but a mixture of them. Similarly, Neural Networks can be trained on multiple inputs, such as images, audio and text, processed accordingly (through CNN, NLP, etc.), to come up with an effective prediction of the target emotion. By doing so, Neural Networks can be better able to capture the subtleties that are difficult to get from each channel individually (e.g. sarcasm), similarly to humans.
System Architecture Considering the task of emotion recognition, that for simplicity we restrict to three classes (Positive, Negative and Neutral)
The Multi-Channel Neural Network Neural Networks can, and should, be trained on multiple types of features. This tutorial walks through how to use the Keras Functional API to augment your networks. Neural Networks are widely used across multiple domains, such as Computer Vision, Audio Classification, Natural Language Processing, etc. In most cases, they are considered in each of these domains individually. However, in real-life settings, it is rarely the case that this is the optimal configuration. It is much more common to have multiple channels, meaning several different types of inputs. Similarly to how humans extract insights using a wide range of sensory inputs (audio, visual, etc.), Neural Networks can (and should) be trained on multiple inputs.
Let’s take, for example, the task of emotion recognition.
Humans do not use a single input to effectively classify the interlocutor’s emotion. They do not use, for instance, the facial expressions (visual), the voice (audio), or the meaning of words (text) of the interlocutor only, but a mixture of them. Similarly, Neural Networks can be trained on multiple inputs, such as images, audio and text, processed accordingly (through CNN, NLP, etc.), to come up with an effective prediction of the target emotion. By doing so, Neural Networks can be better able to capture the subtleties that are difficult to get from each channel individually (e.g. sarcasm), similarly to humans.
System Architecture
Considering the task of emotion recognition, that for simplicity we restrict to three classes (Positive, Negative and Neutral), we can think of the system as the following:
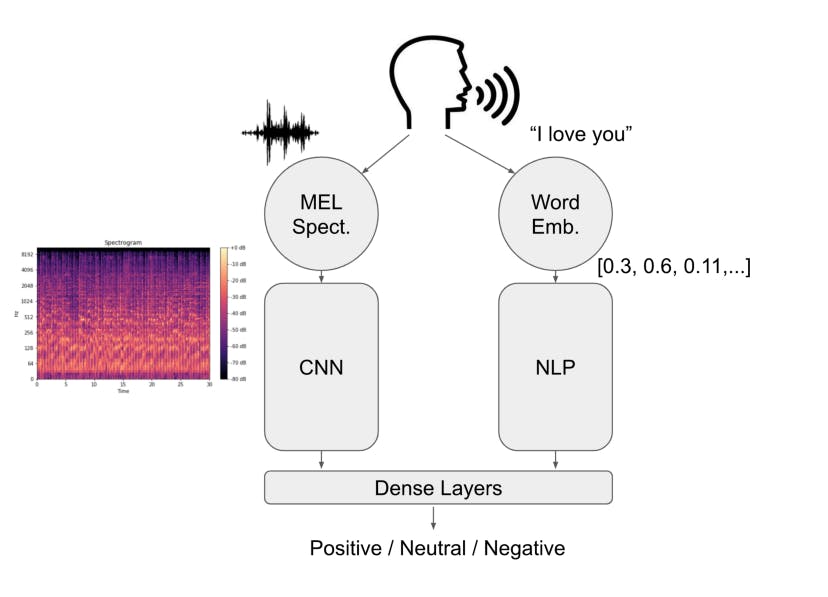
The system picks up the audio through a microphone, computes the MEL Spectrogram of the sound as image and transcribes it into a string of text. These two signals are then used as the inputs to the model, each fed to a branch of it. The Neural Network is, indeed, formed by two sections:
The left branch, performing Image Classification through a Convolutional Neural Network The right branch, performing NLP on the text, using Embeddings.
Image Classification Branch
Right after the sound is collected, the system computes the Spectrogram of the audio signal. The state-of-the-art features for audio classification are MEL Spectrograms and MEL Frequency Cepstral Coefficients. For this example, we will use the MEL Spectrogram.
First of all, we will obviously load the data from a folder containing the audios, split across Training, Validation and Test:
We can then loop through each audio file in these three folders, compute the MEL Spectrogram and save it as an image into a new folder
To do so, we have created a function in the utilities script for Training, Validation and Test. This function uses the librosa package to load the audio file, process it and then save it as an image
Once we have converted each audio signal into an image representing the corresponding Spectrogram, we can load the dataset containing information on the labels of each audio. To properly link each audio file to its Sentiment, we create an ID column containing the name of the image file for that sample
Natural Language Processing Branch
At the same time, we also need to take the text associated with an audio signal and process it using NLP techniques to transform it into a numeric vector so that the Neural Network can process it. Since we already have information on the text from the MELD dataset itself, we can go ahead with it. Otherwise, if the information was not available, to do this, we could use text conversion libraries like Google Cloud’s speech_recognition
Data Pipeline
One of the trickiest aspects of putting together multi-media inputs, is the creation of a custom Data Generator. This structure is basically a function able to iteratively return to the model the next batch of input every time that it is called. Using Keras’ pre-made generator is relatively easy, but there is no implementation allowing you to merge together multiple inputs and make sure that both inputs are fed into the model side by side without errors.
The following code is general enough that it can be used in different settings, not just related to this example. In particular, it takes a folder location, where the images are located, and a “normal” dataset, having samples in the rows and features in the columns. It then iteratively provides the next samples of both images and text features in this case, both in batches of the same size
Neural Network Architecture
Finally, we can create the model having as input images (Spectrogram) and text (Transcriptions), and that processes them.
Inputs
The inputs consist of images made of 64x64 pixels and 3 channels (RGB), and “normal” numeric features, of length 200, representing the encoding of the text Model Inputs images = km.Input(shape=(64, 64, 3)) features = km.Input(shape=(200, )).
Image Classification (CNN) Branch
The Image Classification branch is made of an initial VGG19 network and then a set of custom layers. By using VGG19, we can take advantage of the benefits of using Transfer Learning. In particular, since the model has been pre-trained on the ImageNet dataset, it already starts with coefficients initialised to values meaningful for image classification tasks. The output is then fed into a series of layers that can learn the specific characteristics of this type of images and then outputted to the next common layers Transfer Learning Bases vgg19 = ka.VGG19(weights='imagenet', include_top=False) vgg19.trainable = False
Image Classification Branch x = vgg19(images) x = kl.GlobalAveragePooling2D()(x) x = kl.Dense(32, activation='relu')(x) x = kl.Dropout(rate=0.25)(x) x = km.Model(inputs=images, outputs=x)
Text Classification (NLP) Branch
The NLP Branch uses a Long Short-Term Memory (LSTM) layer, together with an Embedding layer to process the data. Dropout layers are also added to avoid the model overfishing, similarly to what done in the CNN Branch. Text Classification Branch y = kl.Embedding(vocab_size, EMBEDDING_LENGTH, input_length=200)(features) y = kl.SpatialDropout1D(0.25)(y) y = kl.LSTM(25, dropout=0.25, recurrent_dropout=0.25)(y) y = kl.Dropout(0.25)(y) y = km.Model(inputs=features, outputs=y)
Common Layers
We then can combine these two outputs and feed them into a series of Dense layers. A set of dense layers is able to capture information that is available only when both audio and text signals are combined, and is not identifiable from each input individually.
We also use an Adam optimizer with learning rate 0.0001, which is generally a great combination
Model Training
The model can then be trained using the Training and Validation Generators that we previously created by doing:
#Hyperparameters EPOCHS = 13 TRAIN_STEPS = np.floor(train.shape[0]/BATCH) VALIDATION_STEPS = np.floor(validation.shape[0]/BATCH)
Model Training model.fit_generator(generator=train_generator(text_features, BATCH), steps_per_epoch=TRAIN_STEPS, validation_data=validation_generator(validation_features, BATCH), validation_steps=VALIDATION_STEPS, epochs=EPOCHS)
Model Evaluation
Lastly, the model is evaluated on a set of data, for instance the Validation set alone, and then saved as a file to load when used in “Live” scenarios:
#Performance Evaluation
#Validation model.evaluate_generator(generator=validation_generator(validation_features, BATCH))
#Save the Model and Labels model.save('Model.h5')